Use Concurrent Prefix Update to run the Prefix Update function concurrently during the Prefix Resolution function. Concurrent Prefix Update resolves and updates the prefix of each segment whose information was affected by database load, database reorganization, or both, in a single job step.
The following figure shows the general data flow for Concurrent Prefix Update.
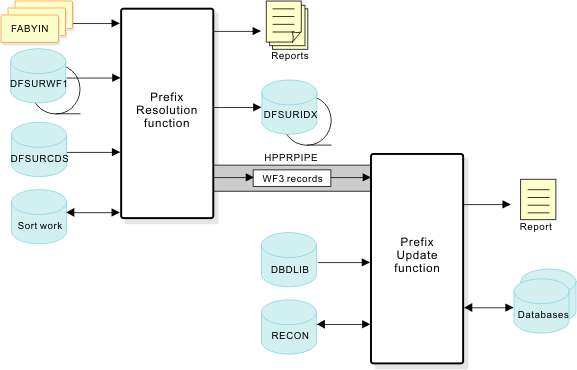
Concurrent Prefix Update uses a data transfer service called HPPRPIPE. HPPRPIPE provides high performance data transfer between tasks running in the address space of IMS™ HP Prefix Resolution. By using HPPRPIPE, the intermediate Work File 2 (WF2) data set and the intermediate Work File 3 (WF3) data sets are eliminated, which results in eliminating much of the I/O for a tape or a direct-access device. If DBRC is active, Concurrent Prefix Update issues a NOTIFY.REORG command for each database that has been updated.