Troubleshooting
Problem
Version 8.7 introduces new features and functions that affect existing Version 8.5 jobs. In some cases, you can set environment variables to retain the Version 8.5 behavior.
Resolving The Problem
Changes to parallel jobs
| Description | Comments |
| In Verison 8.5, in a parallel Transform stage derivation, assigning the DSJOBSTARTTIMESTAMP macro to a column of data type TIMESTAMP (with microseconds) removes the microseconds. | Version 8.7 retains the microseconds precision. |
| You cannot specify a node pool that constrains the location of mmap files that are created by the Lookup and Tsort operators. | Version 8.7 provides a new resource pool named mmap. To use the resource pool, define it in the configuration file. |
| In Version 8.5, only IPv4 is supported. In Version 8.7, both IPv4 and IPv6 are supported. In a mixed environment, Version 8.7 attempts to use IPv6 first, if the network protocol is installed. If an IPv6 connection cannot be made, an IPv4 connection is made. | In a mixed environment in Version 8.7, set the environment variable APT_USE_IPV4 to force an IPV4 connection. |
| In Version 8.7, when a sorted data set is partitioned on the same or a superset of the sort keys and the upstream operator is sequential, a Tsort operator is not inserted because the sort order is retained even though the data set is being partitioned. | To turn off this optimization and use the Version 8.5 behavior, set the environment variable APT_NO_SEQ_SORT_OPTIMIZATION. |
| In Version 8.7, a dfloat (double-precision) data type number has one less precision digit to ensure that data overflow cannot occur. For example, if the float data is 4.99, the exported text string is: Version 8.5 -- "4.9899998E+00" Version 8.7 -- "4.990000E+00" However, because the non-numeric characters in Version 8.5 are represented by one less byte than in Version 8.7, data overflow can occur for a very large or very small number with an exponent that is larger than 99. | To obtain Version 8.5 behavior in Version 8.7, set the environment variable APT_EXPORT_DFLOAT_OLD_BYTE_COUNT to any value. |
| In Version 8.5, the "Signed indicator" property in the Complex Flat File (CFF) stage does not work properly. Whether the property is set or unset, the CFF stage always displays signed data. For example, the data "0055" is displayed as "-0055." In Version 8.7, the "Signed indicator" property works properly. | To obtain the Version 8.5 behavior in Version 8.7, set the environment variable APT_EXPORT_ASCII_SIGNED. |
| In Version 8.7, if a user-specified partition or sort method is inappropriate for a downstream stage, the appropriate method is automatically applied. For details, see the section below, titled "Partition and sort insertion changes for parallel jobs." | To obtain the Version 8.5 behavior in Version 8.7, set the environment variable APT_NO_PARTSORT_OPTIMIZATION. |
| In Versions 8.1, 8.5, and 8.7, the transformer function isValid(type, value) returns true if the value can be converted to the specified data type. For example, the return value is 1 for both isValid ("int64," "123.456") and isValid ("int32," 123.456."). In Version 8.0.1 and earlier, the return value is 0 for both functions. | To obtain Version 8.0.1 and earlier behavior, set the environment variable APT_ISVALID_BACKCOMPAT |
For each job, the DataStage parallel engine generates a plan that is based on the job definition and the configuration file. A key part of the plan is ensuring that the appropriate partitioning and sorting is applied to each link of the job. The requirements of the job are implemented by inserting partition methods and sort operations on specific keys on input links to stages.
When you use the default Auto method for partitioning or sorting, the parallel engine selects the most appropriate method based on the requirements of the stage. However, if you know about the data ordering, you might choose to optimize the flow by using a combination of the Auto method and choosing specific partitioning and sorting methods.
In Version 8.5 and earlier, if you specify a partitioning or sorting method, the method is never changed, even if it is apparent that it does not meet the requirements of the downstream stage.
In Version 8.7, if the specified partitioning or sorting method is inappropriate for a downstream stage, the method is automatically changed to accommodate the stage. If you want to retain the Version 8.5 and earlier behavior, set the environment variable APT_NO_PARTSORT_OPTIMIZATION.
Examples of changes that might affect jobs that were created in Version 8.5
Example 1: User-specified sort keys do not fulfill the requirements of the downstream operator
In the following figure, the Sort stage sorts on the key field "a," and the Remove Duplicates stage works on key field "b." In Version 8.5, the parallel engine issues a warning about the incorrect sort, but allows the sort to remain in the job. In Version 8.7, the parallel engine issues the same warning, replaces the user-specified sort with a sort that has the same name but that has the correct keys and options, and issues one of the following warning messages to indicate the sort was modified.
- When checking operator: User inserted sort "tsort" does not fulfill the sort requirements of the downstream operator "remdup.
- When checking operator: User inserted sort "tsort" ({key={value=a, subArgs={asc}}}) has been modified to fulfill the sort requirements of the downstream operator "remdup" ({key={value= b, subArgs={asc}}}).

Example 2: User-specified Don't Sort option is incorrect because of the repartitioning of the data
In Version 8.1, the job fails because of unsorted data. In Version 8.7, the parallel engine replaces the user-specified sort with a sort that meets the key requirements, and issues a warning to indicate that the sort was modified.
Example 3: User-specified Same partitioning doesn't fulfill the sort requirements of the downstream operator
In the following figure, the Remove Duplicates stage works on key field "a," and the Differences stage works on key field "b." Because the link between the two stages is configured for Same partitioning, the incorrect sort key "a" is used. In Version 8.5, The Same partitioning on the link remains and a tsort with key "b" is inserted on the Same link. A Hash partitioner and a tsort both with key "b" are inserted on the Auto link. In Version 8.7, a Hash partitioner and a tsort, both using key "b," are inserted on the Same and the Auto links.
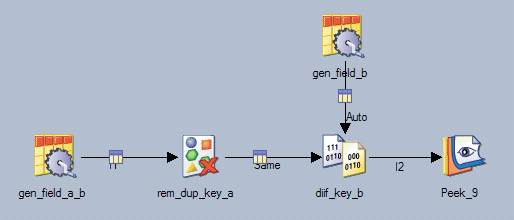
Example 4: User-specified partitioning or sort keys on one ore more input links of a multiple-link operator is incorrect
In the following figure, there is a join on keys "a" and "b," and there are two Remove Duplicates on keys "a" and "c." Both inputs to join are set to partition with hash and perform sort, but link hash_sort_a_c has hash and sort on keys "a" and "c," while link hash_sort_a_b has hash and sort on keys "a" and "b." Link hash_sort_a_b is correctly sorted, but link hash_sort_a_c is partitioned and sorted on keys "a" and "c."
In Version 8.5, the parallel engine does not change the specified hash and tsort, and the multiple-link operator might produce incorrect results. In Version 8.7, the parallel engine issues the following warnings indicating that link hash_sort_a_c has insufficient partitioning or sort keys and inserts a sort and hash partitioner with keys "a" and "b," unless Entire was user-specified.
- When checking operator: User inserted sort "tsort(0)" does not fulfill the sort requirements of the downstream operator "APT_JoinSubOperatorNC in innerjoin."
- When checking operator: User inserted sort "tsort(0)" ({key={value-a, subArgs={asc}}, key={value=c, subArgs={asc}}}) has been modified to fulfill the sort requirements of the downstream operator "APT_JoinSubOperatorNC in innerjoin" ({key={value=a, subArgs={asc}}, key={value=b, subArgs={asc}}}).
- When checking operator: User specified partitioning method on the input link of "tsort(0)"({key={value=a}, key={value=c}}) has been modified to fulfill the partitioning requirements of the downstream operator "APT_JoinSubOperatorNC in innerjoin" ({key={value=a}, key={value=b}}).
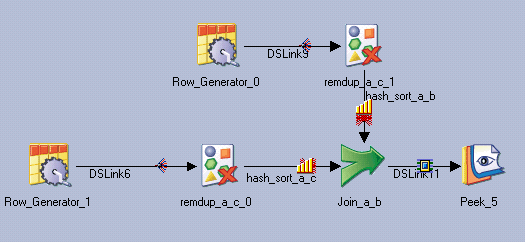
Example 5: User-specified hash and sort keys do not fulfill the requirements of the down stream operator, and the environment variable APT_NO_SORT_INSERTION was specified but the environment variable APT_NO_PART_INSERTION was not specified
In Version 8.5, the parallel engine does not change the user-specified hash and tsort, and the multiple-link operator might produce incorrect results. In Version 8.7, the parallel engine inserts a new hash partitioner but does not insert a new tsort. The multiple-link operator might produce incorrect results.
To disable the automatic insertion of partitioning and sorting, you must set both APT_NO_SORT_INSERTION and APT_NO_PART_INSERTION.
DSExecute parameter masking
In Version 8.7, if an encrypted parameter such as a password, is present in the Command or Output arguments of the Basic subroutine DSExecute.B, the parameter is replaced with a fixed number of asterisks. So after returning from the subroutine, the string is masked. This masking takes place only if the subroutine is called from within a job.
To retain the Version 8.5 behavior, set the environment variable DS_EXECUTE_NO_MASKING.
QualityStage standardization rule set enhancements and fixes
Enhancement: Use the default value "0" for the match field that represents the number of match words, for example NumofMatchStreetWords, for all delivered rule sets.
Rule sets affected: ARADDR, ARNAME, CLADDR, CLNAME, ESADDR, MXADDR, MXNAME, PEADDR, PENAME
Change to output: Yes, to the match field.
Fix: Resolved the issue of repeated data when the match field has more than six tokens.
Rule sets affected: ARADDR, ARNAME, BRNAME, CANAME, CLADDR, CLNAME, DEADDR, DENAME, ESADDR, ESNAME, FRADDR, FRNAME, BGNAME, ITADDR, ITNAME, MXADDR, MXNAME, NLADDR, NLNAME, PEADDR, PENAME, USNAME
Change to output: Yes, to the match fields only.
Enhancement: Improved NameType values by incorporating Name Processing Options in identification.
Rule sets affected: DENAME, ESNAME, FRNAME, GBNAME, NLNAME
Change to output: Yes, to the NameType field only.
Enhancement: Added parsing rule for the match fields to concatenate letters on each side of an apostrophe
Rule sets affected: ARNAME, BRNAME, CLNAME, DENAME, MXNAME
Change to output: Yes, to the match fields only.
Fix: The misspelling of Distrito Reverse Soundex column was changed from DistritoaRVSNDX to DistritoRVSNDX.
Rule set affected: PEAREA
Change to output: Yes, to DistritoRVSNDX
Fix: Populate the GenderCode column with a blank instead of a "U" when the gender cannot be determined.
Rule set affected: BRNAME
Change to output: Yes, to the GenderCode column.
Enhancement: USADDR processing was improved in the following ways:
- BLVE, NORT, SOUT, and PLAZ were added to the Classification file.
- The word COURTHOUSE was standardized so that COURT is not assigned to PrefixStreetType.
- Patterns that have mixed class (@) for a unit value are handled, for example, STE101B and SUITE3A3.
- Apostrophes are explicitly handled.
- The word SAINT standardizes to ST when followed by another word for StreetName.
- The word ONE as HouseNumber standardizes to 1 instead of being ONE as part of StreetName.
- The pattern UT is processed, for example SUITE ST.
- When there is a mixture of alphanumeric characters in a unit value, if two numbers and then a space remains, the space is removed.
- House numbers that have a preceding pound sign (#) are no longer assigned to UnitValue.
- The standardization of ST MARY is improved. With a StreetSuffixType, ST MARY becomes StreetName. Without a StreetSuffixType, ST becomes PrefixStreetType, and MARY becomes StreetName.
- The input patter ^P+T is similarly standardized.
Change to output: Yes.
Was this topic helpful?
Document Information
Modified date:
16 June 2018
UID
swg21517119