Question & Answer
Question
How do I migrate from the IDoc stage in 6.5 to the IDoc connector stages in 7.0?
Answer
IDoc stages designed with the Pack 6.5.x cannot be upgraded automatically to the new IDoc connector stages in version 7. If you want to migrate existing IDoc jobs designed with the 6.5.x you must perform the steps that are described here.
Note: When you install version 7 of the SAP Pack on an Information Server 8.5 where 6.5.x was already installed, the 6.5.x IDoc stages remain fully functional. The IDoc connector stage of version 7 will be displayed as new stages in the palette.
The IDoc connector stages of V7 have a different column schema than in 6.5.x. Listed below are the additional fields on the input /output links for IDoc segments of both IDoc load and IDoc extract:
- ADM_DOCNUM (VarChar(250)): The IDoc ID.
- ADM_SEGNUM (VarChar(250)): The segment ID. It must be unique for each IDoc but the value can be the same for different IDocs.
- ADM_PSGNUM (VarChar(250)): The segment ID of the parent of this segment (see ADM_SEGNUM).
- For load, this can be any string.
For extract, the value will be a string with a maximal length of 16 containing only digits.
- For load, this can be any string.
For extract, the value will always be a string with maximal length of 6 containing only digits.
- For load, this can be any string. When loading root segments this value will be ignored (root segments don't have parent segments),
For extract, the value will always be a string with maximal length of 6 containing only digits. When extracting root segments the value will be "000000".
Note that in 6.5.x, the column schema for IDoc load did look different in that there were different fields of the form SEG_*_P_KEY, SEG_*_F_KEY, or IDOC_*_F_KEY depending on the segment structure. The IDoc extract column schema, on the other hand, did have those three fields but with shorter lengths.
This new column schema has the following advantages:
- Parallelism can be achieved through partitioning the data on the ADM_DOCNUM column (for example, using a hash partitioner).
- The column schemas for IDoc load and IDoc extract are now the same. The column schema of an extracted IDoc structure can be re-used for load without any changes.
- The size of 250 characters for each additional field allows for easier construction of key for the IDoc and segment IDs for IDoc load. Those numbers can typically be constructed by concatenating respective key attributes of source tables. The length of 30 in the 6.5.x IDoc stages is too short in situations when the concatenation of those keys is longer than 30.
To migrate a job with IDoc stages from 6.5.x to 7, perform the following steps:
- Open the job in DataStage Designer.
- Optional: Ensure that there is a Transformer stage on each link to / from the IDoc load / extract stage. This is not necessary, in general, but since the column schema on the link is changed, the transformer stage ensures that connected stages are not affected.
- Remove the IDoc stage by right-clicking the stage and selecting Delete.
- Drag the corresponding IDoc connector stage from the palette (for example, IDoc Load connector Stage for load, IDoc Extract Connector stage for extract) and connect it to the links that were previously connected to the old IDoc stage.
- Double-click the IDoc connector stage to open it.
- Configure the IDoc Connector stage. The UI of the Connector stage is almost identical as for the 6.5 stages. In particular, selecting the IDoc type and IDoc components is done similarly.
- Open each of the stages connected to the IDoc segment links and map the column schemas as described below. If you have added transformer stages as described in step 2 above you can use these transformers to do the mapping.
- Save and compile the job.
Mapping the column schemas
In the following section, the term "old schema" refers to the column schema of the 6.5.x IDoc stages. The term "new schema" refers to the one of the V7 IDoc Connector stages.
IDoc Extract:
The only change between the old and new schema is that the lengths of the ADM* fields will be increased.
Since the original job was designed by using smaller lengths, there are typically no additional changes necessary in the job design as such. An exception might be if the job logic assumes that one or more of the ADM* fields has exactly the lengths as created by the old IDoc stage.
There might also be issues triggered by external resource that expect the smaller lengths. For instance, if a database was created from the old schema, the fact that the lengths of the respective database columns is now 250 might lead to warnings or errors.
IDoc Load:
For load, the number and semantics of the columns differ, so some effort must be put into modifying the jobs.
The SEG_*_P_KEY and SEG_*_F_KEY columns can be mapped directly (that is. without any transformations) to the ADM_SEGNUM and ADM_PSGNUM fields in the new schema. Note that the old schema requires uniqueness for those keys, whereas the new schema does not and will be able to handle them.
For root segments, the IDOC_*_F_KEY columns can be used directly for the ADM_DOCNUM field because both denote IDoc ID. The ADM_PSGNUM on a root segment can be set to any value. The IDoc stage will ignore this value because it knows from the IDoc structure that it does not have a parent.
The only change that cannot be resolved by a direct mapping from the old to the new schema is the ADM_DOCNUM field on non-root segments. In the old schema, the IDoc number did not exist on the link. Instead, the SEG_*_P_KEY field was required to be unique.
See Fig. 1 for a graphical depiction of this mapping.
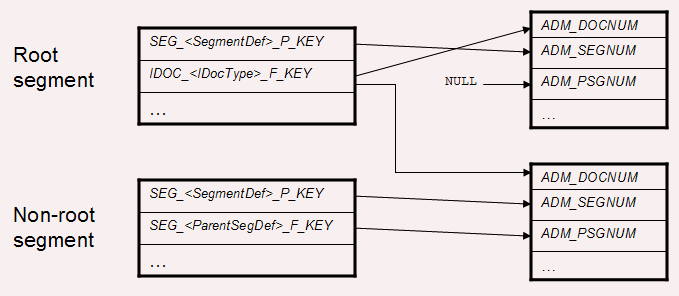
Fig. 1: Mapping the 6.5.x to the 7.0 IDoc load schema.
A very common way to construct the _P_KEY and _F_KEY fields is this example:
- The primary key of the business object (for example, customer number, order number) is used as the IDOC_*_F_KEY
- The SEG_*_P_KEY is created by a combining the mentioned primary key with another ID (probably another primary key used in a source data table)
In this case, the ADM_DOCNUM column on non-root segments can be computed by extracting the primary key from the SEG_*_P_KEY column value. If you did a simple string concatenation, it might be possible to just take the first n characters (if you know that your primary key is exactly n characters long).
Was this topic helpful?
Document Information
Modified date:
16 June 2018
UID
swg21571402